안녕하세요, 이번엔 이벤트드리븐 서비스의 개선작업을 하다가 알게된 cloudwatch 통계지표 조회방법을 공유드립니다.
이 작업을 하게된 이유를 말씀드리자면 이렇습니다.
현재 SQS 를 이용한 이벤트드리븐 환경에서 동작하는 서비스가 있습니다.
이런 저런 정보들을 동기화하기 위한 목적으로 사용하고 있고, 이 서비스는 멀티쓰레드 환경에서 동작하도록 되어있습니다.
혹시라도 이벤트가 지연될 경우를 대비해서 쓰레드 개수를 수시로 수동조절할 수 있도록 구성해두었죠.
그리고 지연이 발생하여 SQS 메시지가 발행된 뒤 일정 시간동안 처리를 못하여 큐에 계속 남아있게되면 alert가 발생하도록 되어있습니다.
즉, SQS의 ApproximateAgeOfOldestMessage 지표값을보고 너무 오래동안 처리가 안될 경우 alert를 받고 수동으로 쓰레드 개수를 조절하는 형태로 위기를 벗어나고 있습니다. 그런데 이 드물디 드문 사건이라도 개발자라면, 그리고 가능한 케이스라면 그냥 전부 다 자동화를 해놓아야 하지 않을까 생각이 들어 개선 작업에 들어갔습니다.
일단 SQS에서 제공하는 모니터링 지표는 아래와 같습니다. (AWS 콘솔화면의 모니터링 탭에서 볼 수 있는 것들입니다)
Approximate Number Of Messages Delayed
Approximate Number Of Messages Not Visible
Approximate Number Of Messages Visible
Approximate Age Of Oldest Message
Number Of Empty Receives
Number Of Messages Deleted
Number Of Messages Received
Number Of Messages Sent
Sent Message Size
이 지표에 해당하는 통계수치는 cloudwatch 에서 수집이 됩니다.
클라우드워치에서 수집된 데이터를 가지고 모니터링탭에 그래프로 보여주는 것이죠.
이제 제가 원하는 Approximate Age Of Oldest Message 에 대한 데이터를 뽑아보도록 하겠습니다.
일단 앱의 구성은 다음과 같습니다.
SpringBoot 2.3.x
AWS Java SDK 1.11.x
Java 11
AWS java sdk 에서는 cloudwatch 서비스에서 제공하는 API를 호출하여 클라우드워치 데이터를 조회할 수 있도록 cloudwatch client를 제공합니다. 제일 먼저 이 클라이언트를 빈으로 등록합니다.
@Configuration
public class AWSConfig {
private AWSCredentialsProvider awsCredentialsProvider() {
List<AWSCredentialsProvider> credentialsProviders = new ArrayList<>();
credentialsProviders.add(new InstanceProfileCredentialsProvider(true));
credentialsProviders.add(new ProfileCredentialsProvider());
return new AWSCredentialsProviderChain(credentialsProviders);
}
@Bean
public AmazonCloudWatch cloudWatchClient() {
return AmazonCloudWatchClientBuilder.standard()
.withCredentials(awsCredentialsProvider())
.withRegion(Regions.fromName("ap-northeast-2"))
.build()
;
}
}
그리고 서비스 레이어에서 이 cloudWatchClient를 가져다 써보겠습니다.
private void getQueueStatus(String queueName) {
long currentMillis = System.currentTimeMillis();
long fiveMinutesInMillis = 5 * 60 * 1000;
GetMetricStatisticsRequest statisticsRequest = new GetMetricStatisticsRequest()
.withNamespace("AWS/SQS").withMetricName("ApproximateAgeOfOldestMessage")
.withStatistics(Statistic.Maximum).withPeriod(300)
.withStartTime(new Date(currentMillis - fiveMinutesInMillis))
.withEndTime(new Date(currentMillis))
.withDimensions(new Dimension().withName("QueueName").withValue(queueName));
GetMetricStatisticsResult result = cloudWatch.getMetricStatistics(statisticsRequest);
log.debug("dataPoints: {}", result.getDatapoints());
}
cloudWatchClient 를 이용하여 통계수치 데이터를 조회하려면 GetMetricStatisticsRequest 객체를 만들어서 넣어주어야 합니다.
이 객체에 설정해줘야 하는 값들 중 필수적인 것들만 설정해보았습니다.
간략히 설명하자면 다음과 같습니다.
withNameSpace: cloudwatch에서 서비스를 구분하는 값 (ex. "AWS/SQS", "AWS/EC2", etc.)
withMetricName: 조회하고자하는 메트릭 명
withStatistics: Statistic 에서 제공하는 통계기준(?), enum으로 정의되어있음
SampleCount
Average
Sum
Minimum
Maximum
withStartTime, withEndTime: 조회하려는 데이터 구간 (데이터의 시작 시점과 종료 시점)
withPeriod: 조회하려는 데이터 구간 내에서의 데이터 간격. 예를들면 지난 1시간 동안 몇 분 간격으로 데이터를 조회할지를 의미. 초단위값
withDimensions: SQS의 경우 "QueueName" 하나만 있고, 이 값으로 어떤 sqs에 대한 데이터인지 구분 가능.
설정값은 현재 지난 5분동안(from endTime to startTime) 5분간격(period)의 데이터를 조회하도록 되어있으므로 1개의 data point 가 조회가 됩니다. 그리고 unit은 초단위로 나옵니다.
위 코드를 실행해서 조회한 sqs의 Approximate Age Of Oldest Message 지표값은 다음과 같이 출력됩니다.
dataPoints: [{Timestamp: Thu Dec 29 16:08:00 KST 2022,Maximum: 249.0,Unit: Seconds,}]
설정값을 변경하여 period를 60으로 넣어서 실행하면 5개가 조회됩니다.
dataPoints: [{Timestamp: Thu Dec 29 17:03:00 KST 2022,Maximum: 3254.0,Unit: Seconds,}, {Timestamp: Thu Dec 29 17:07:00 KST 2022,Maximum: 3554.0,Unit: Seconds,}, {Timestamp: Thu Dec 29 17:05:00 KST 2022,Maximum: 3433.0,Unit: Seconds,}, {Timestamp: Thu Dec 29 17:06:00 KST 2022,Maximum: 3491.0,Unit: Seconds,}, {Timestamp: Thu Dec 29 17:04:00 KST 2022,Maximum: 3370.0,Unit: Seconds,}]
조회된 5개의 데이터는 지난 5분 구간(startTime, endTime)에서 1분 간격(period) 데이터를 조회했을 때의 결과입니다. 그리고 이 값은 Approximate Age Of Oldest Message, 즉, 대략적으로 얼마나 오래되었는가를 나타내는 값이므로 1분 간격 데이터를 조회한다면 약 1분(60초)의 시간차이가 있겠죠. 출력된 데이터의 순서가 시간순이 아니니 시간순으로 정렬해보면 약 1분 정도 차이가 난다는 것을 확인할 수 있습니다.
[
{Timestamp: Thu Dec 29 17:03:00 KST 2022,Maximum: 3254.0,Unit: Seconds,},
{Timestamp: Thu Dec 29 17:04:00 KST 2022,Maximum: 3370.0,Unit: Seconds,}
{Timestamp: Thu Dec 29 17:05:00 KST 2022,Maximum: 3433.0,Unit: Seconds,},
{Timestamp: Thu Dec 29 17:06:00 KST 2022,Maximum: 3491.0,Unit: Seconds,},
{Timestamp: Thu Dec 29 17:07:00 KST 2022,Maximum: 3554.0,Unit: Seconds,},
]
17:03 에서 17:04는 예외적으로 약 2분 차이가 나네요 ^^;;
이상으로 AWS cloudwatch API로 SQS의 metric을 조회하는 방법에 대해 알아보았습니다.
저는 이렇게 조회한 데이터를 가지고 일정 시간을 넘어설 경우 쓰레드 개수를 scale in/out 하도록 서비스를 구현했습니다.
운영환경에 이런저런 개발이 계속 진행되고 데이터도 쌓이고 하다보니 점점 무거워지고 있는 와중에 dba쪽에서 slow query 관련하여 문의가 들어왔고 확인하다보니 다른 이슈가 확인되었다. readOnly 트랜잭션으로 묶어놓은 쿼리인데 reader쪽에서 실행되어야 할 쿼리가 writer쪽에서도 실행이 되고 있는 현상이 지속되고 있었다.
현재 애플리케이션은 SpringBoot 2.x + MariaDB connector 2.7.x + HikariPool + MyBatis 사용하도록 구성된 상태.
그리고 jdbc url은 아래와 같이 writer 클러스터 주소만 넣어서 사용하고 있었다. 내가 이렇게 설정한건 아니었고 이렇게 해도 aurora 옵션을 쓸 경우 자동으로 reader쪽으로 readOnly 쿼리가 실행된다고 누군가가 그래서 뭐 그러려니 하고 있었는데 이런 이상한 현상이 확인된 것이다. ( >,.< )
DEBUG 88239 --- [nio-8080-exec-1] org.mariadb.jdbc.MariaDbConnection : conn=817636(M) - set read-only to value true
DEBUG 88239 --- [nio-8080-exec-1] o.m.j.i.protocol.AbstractQueryProtocol : System variable change : autocommit = OFF
{{쿼리 실행}}
DEBUG 88239 --- [nio-8080-exec-1] o.m.j.i.protocol.AbstractQueryProtocol : System variable change : autocommit = ON
DEBUG 88239 --- [nio-8080-exec-1] org.mariadb.jdbc.MariaDbConnection : conn=53856(S) - set read-only to value false
로그상으로는 도대체 실제로 어느 클러스터 주소에서 쿼리가 실행되는지 알 수가 없었다.
그래서 운영환경에서 사용하고있는 mariaDB 커넥터와 동일한 버전의 소스코드에 로그를 여기저기 추가하면서 추적을 시작했고,
다음과 같은 현상을 확인했다.
writer 클러스터 주소를 기준으로 신규 커넥션을 생성된다.
readOnly 쿼리가 writer쪽에서 실행된 뒤에 failover 프로세스가 실행되면서 mariaDB FailoverLoop에서 reader쪽 커넥션이 생성되어 pool에 들어간다.
이후의 readOnly 쿼리들은 정상적으로 reader쪽에서 실행된다.
이제 궁금한 점이 생겼다.
커넥션의 생성주기에 따라 신규 커넥션을 생성하게되면 reader쪽 커넥션은 사라지는지?
신규 커넥션 생성시 reader host가 포함되도록 할 수 있을지..? (이렇게 할 수 있으면 1번과 같은 현상은 없어질테니)
그렇게하면 readOnly 쿼리가 항상 reader로 들어가는지?
1번 케이스의 경우 maxLifeTime 설정값을 30초로 설정해서 테스트해보았고, reader쪽 커넥션은 사라지게된다. readOnly 쿼리가 reader에서 실행되려면 위에 말한 failover 과정이 다시 필요하다. 즉, maxLifeTime이 지나 커넥션을 새로 생성하게 될 경우 failover 프로세스가 실행되어야 reader를 사용할 수 있게 된다. (아래 2번 케이스에 대한 내용까지 확인하면 알겠지만 어디까지나 url 설정에 메인 클러스터 주소만 넣었을 경우이다.)
2번 케이스의 경우 jdbc url 설정에 reader 클러스터의 주소를 추가해주면 된다. 기존 설정과 변경한 설정은 다음과 같다.
이렇게 reader cluster의 주소가 추가된 jdbc url을 사용할 경우 항상 reader 클러스터쪽으로 readOnly 쿼리가 실행되는 것을 확인할 수 있었다. 혹시라도 url 뒤쪽에 파라미터값을 사용한다면 파라미터값들은 제일 마지막에 한번만 붙여주면 된다. 예를들어 파라미터값을 아래처럼 넣게되면 mariaDB 커넥터에서 url 파싱할 때 뒤 쪽 url이 사라지게 되니 주의!!! 즉, 모든 클러스터에 동일한 파라미터값을 사용해야 한다는 것 !!
그냥 얼핏 듣기로는 메인클러스터 주소만 넣어주소 jdbc url에 aurora 옵션을 넣어줄 경우 readOnly 트랜잭션은 자동으로 reader 쪽으로 들어간다고 들었었으나 그렇지 않다는 것을 확인한 디버깅이었다.
결국 결론은 이렇다. 클러스터 주소가 writer, reader가 별도로 있을 경우 (아마 AWS aurora를 클러스터링해서 사용할 경우 다 이럴 것이다) 개발자 입장에서는 writer, reader 두 클러스터 주소를 jdbc url에 넣어주어야 readOnly 트랜잭션이 항상 정상적으로 reader 클러스터에서 실행되게 된다.
참고로...mariaDB connector 3.x 버전에서는 aurora 옵션을 지원하지 않는단다...
Warning: consider KEYS as a command that should only be used in production environments with extreme care. It may ruin performance when it is executed against large databases. This command is intended for debugging and special operations, such as changing your keyspace layout. Don't use KEYS in your regular application code. If you're looking for a way to find keys in a subset of your keyspace, consider using SCAN or sets.
3) value 타입 확인 (value 타입에 따라 조회 명령어가 다름)
redis.0001.apn.cache..amazonaws.com:6379> get "EmployeeName:Tom Johnson" (error) WRONGTYPE Operation against a key holding the wrong kind of value
redis.0001.apn.cache..amazonaws.com:6379> type "EmployeeName:Tom Johnson"
제가 관리하는 시스템 중 하나가 주로 카프카 메시지를 컨숨하여 처리하는 일을 하는 시스템입니다.
여러 개의 인스턴스가 존재하고 모두 동일한 소스코드가 배포되어있죠.
소스코드에는 JPA를 이용한 CRUD 로직이 들어있습니다.
문제가 없던 시스템인데 관련부서에서 파티션 개수를 늘리면서 문제가 생겼습니다.
단순히 파티션 개수가 늘어난게 문제가 아니라 그쪽에서 보내는 카프카 메시지의 특성과도 관련이 있었죠.
파티션마다 서로 다른 인스턴스에서 처리하지만 각 메시지에는 서로 중복된 데이터의 내용이 들어가 있는 형태였고 (이건 뭐 제가 어찌 할 수 없는 것이죠), 동일한 데이터를 서로 다른 인스턴스에서 JPA를 이용해서 처리하다가 드물게 ObjectOptimisticLockingFailureException 이 발생하기 시작했습니다.
예를들어 인스턴스 1번에서 {A, B} 라는 메시지를 처리할 때 인스턴스 2번에서 {A,C}, 3번 인스턴스에서 {A,D} 메시지를 처리하면서 A 데이터를 3대의 인스턴스에서 동시에 처리하려고 한거죠. 세 개의 메시지는 서로 다른 데이터도 들고있으므로 무조건 처리를 해줘야 하는 것들이었습니다.
이걸 어떻게 할 까 고민하다가 SQS를 DLQ를 이용하여 Lambda 와 연결시켜 일정 시간이 지난 뒤에 수동동기화 API를 호출하도록 구성하기로 했습니다.
이렇게 한 이유는 가장 빠른시간에 추가적인 소스구현 없이 효과적으로 목적을 달성할 수 있었기 때문입니다.
만약 DLQ로 들어오는 메시지가 많아진다면 소스코드를 구현하는게 비용측면에선 더 효율적입니다.
인스턴스는 어차피 떠있어야 하는거고 람다를 제거할 수 있으니 람다에서 발생하는 비용이 줄어듭니다.
하지만 소스코드 구현시 고려해야할 점이 있죠. 인스턴스가 여러개 떠있지만 하나의 인스턴스에서만 DLQ의 메시지를 처리하도록 해야한다는 거죠. 그렇지 않으면 또 처리에 실패하는 경우가 발생할 테니까요. 그리고 모든 인스턴스에 동일한 소스코드가 배포되어야 하는데 하나의 인스턴스에서만 실행이 되도록 하려면 또 이런저런 코드를 작성해야 하다보니 람다를 이용하기로 했습니다.
아무튼, SQS를 DLQ로 이용하고, Lambda 함수를 연결시켜 일정 시간뒤에 수동API를 호출하여 실패했던 메시지에 대한 정보를 읽어와서 처리하도록 했습니다.
SQS Lambda Trigger 설정
이렇게 설정해놓으면 SQS 메시지가 발행될 때마다 Lambda 함수를 실행하는데 Lambda 함수에서는 API를 호출하도록 구성했습니다. 람다 트리거에 대한 내용을 AWS에서는 다음과 같이 설명하고 있습니다.
You can configure your Amazon SQS queue to trigger an AWS Lambda function when new messages arrive in the queue. Your queue and Lambda function must be in the same AWS Region. A Lambda function can use at most one queue as an event source. You can use the same queue with multiple Lambda functions. You can't associate an encrypted queue that uses the AWS-managed CMK for Amazon SQS with a Lambda function in a different AWS account.
저의 경우에는 필요없긴하지만, 하나의 SQS에 여러개의 람다함수를 연결하여 사용할 수 있다는 점이 좋아보이네요.
Python은 공부한적 없으나, 자바는 컴파일언어라 코드를 직접 AWS콘솔에서 작성할 수 없어서 python으로 작성했습니다.
내용은 별거 없고 event에 SQS 메시지의 내용이 들어오기 때문에 event에서 메시지의 body 내용을 추출하여 message 변수에 넣고 이것을 API 호출할 때 사용한것이 다입니다. 여기서는 employeeId 값이 SQS 메시지에 {"employeeId":1234} 형태로 들어있었다면, 저기서 1234 값을 추출하여 api 호출할때 path variable로 넣어서 https://company.com/employees/1234 를 호출하도록 한거죠.
위 코드상에선 에러가 발생하면 그냥 로깅하거나 에러코드 리턴하도록 해놓았는데, 에러건이 많이 발생한다면 슬랙알람을 보내도록 하는 것도 좋을 것 같습니다.
이상으로 SQS와 Lambda를 이용한 분산처리시스템에서의 DLQ 처리에 대한 기록을 마칩니다.
오늘은 AWS Elasticsearch(이하 ES)의 인덱스를 자동으로 삭제하는 방법에 대해서 알려드립니다.
저는 AWS ES를 로깅을 위해서 사용하고 있습니다. 로그 검색 속도가 빨라 디버깅시 원인파악을 빠르게 할 수 있어서 좋죠. 특정 트래킹 ID로 특정 프로세스의 로그들을 하나로 묶어주면 해당 프로세스의 로그만 검색이 가능하여 편리합니다.
아무튼, 이렇게 로그를 쌓기 위해서 사용하는 ES가 용량이 부족해지면 별다른 에러나 알람을 주지않고 더이상 로그가 쌓이지 않게되는 현상이 있습니다. 운영 환경에서는 그런 일이 없도록 하기 위해서 큐레이터 설정을 하여 사용중입니다. 이 설정은 인프라 전문팀과 논의하여 설정을 했었습니다. 큐레이터를 이용하려면 좀 귀찮은 작업들이 수반됩니다. 그래서 개발환경에서는 큐레이터 설정 없이 수동으로 가끔씩 인덱스를 삭제해주곤 했죠. ES 버전이 올라가면서 이제는 키바나에서 간단히 설정해주면 자동으로 특정 기간이 지난 인덱스를 삭제할 수 있게끔 되었습니다. 참고로 오리지날 ES에서는 이 기능을 ILM (Index Lifecycle Management) 기능이라고 부르는데 AWS에서는 ISM (Index State Management)라고 합니다.
우선 제가 사용중인 AWS ES 버전은 7.9 입니다. 동일한 7.9 버전이라도 패치버전에 따라 키바나 메뉴가 조금 상이합니다.
지금 우리는 인덱스 상태를 관리하는 설정을 하는 것입니다. 따라서 policy 내에 상태에 대한 정의를 해주고 있습니다.
policy_id는 Name policy에 명명해주었던 이름을 그대로 사용하고, default_state 를 hot 이라는 상태로 설정해주었습니다.
여기서 우리는 두 가지 상태를 정의해서 사용하고 있습니다. hot 과 delete.
인덱스의 기본상태로는 hot을 정의를 해주었고 그 상태의 인덱스들은 transitions에 설정되어있는 조건에 따라 상태를 변경하게 됩니다. 즉 max_index_age가 30d (30일)이 지나면 상태를 delete로 변경(transition)하게 되죠. 그렇게 delete 상태가 된 인덱스들은 delete 상태 정의의 actions에 있는 delete 설정으로 인해 삭제되게 됩니다.
이제 ISM 정책 생성을 완료하였습니다.
이렇게 정책을 생성한 뒤에는 기존 인덱스들에 대해서 해당 정책을 적용해주어야 합니다.
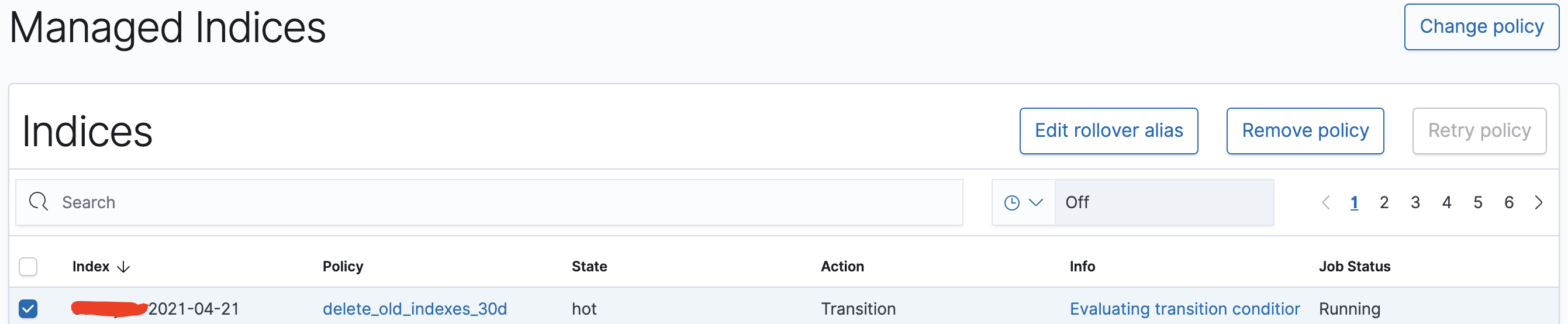
정책을 저장한 뒤에 좌측 메뉴에서 Indices 로 들어가보면 현재 인덱스들 목록이 출력됩니다.
인덱스 목록
목록에서 하나 이상의 인덱스를 선택하면 우상단의 Apply policy 버튼이 활성화 됩니다. 버튼을 클릭하면 정책이 반영되고 새로고침을 해보시면 Managed by Policy 값이 No 에서 Yes로 변경됩니다. .kibana 인덱스처럼 잘 모르면 건들지 말아야하는 인덱스들도 여기 목록에 조회가 되기 때문에 전체 선택하여 정책을 적용시킬 때에는 그런 인덱스들이 포함되어있지 않은지 잘 확인하셔야 합니다. 만약 잘못 적용했다면 적용 취소도 가능합니다.
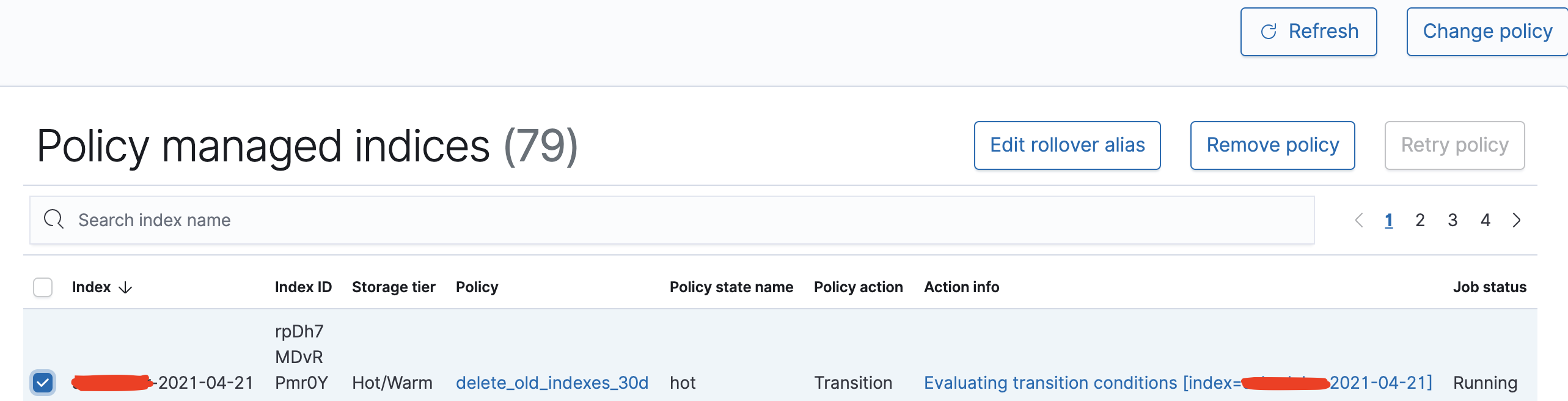
정책을 적용한 인덱스들을 여기서는 Managed Index라고 부릅니다. 따라서 적용을 취소하려고 할 때에는 Managed Indices 또는 Policy managed indices 메뉴로 들어가서 인덱스를 조회하여 처리합니다.
구 버전 화면최신 버전 화면 (R20210331)
인덱스를 선택하고 Remove policy(삭제) 하거나 Change policy(변경)이 가능합니다.
이상으로 AWS ES에서 ISM을 활용하여 인덱스 자동삭제 정책을 생성 및 적용하는 방법을 알아보았습니다.
스텝을 따라하면서 무슨 명령어인가 보았더니 새로운 인덱스를 만들고 alias를 연결해주고 기존 인덱스의 내용을 넣어주는 것이었다.
그리고 그렇게 따라하다가 제일 마지막 스텝인 백업 인덱스 삭제하기 전에 인덱스 패턴(saved object) 목록을 조회해보니 똑같은 인덱스 패턴이 여러개가 조회가 되었다. 그래서 동일한 패턴은 하나씩만 남겨놓고 모두 삭제하였다. 그리고 discover로 들어가니 정상적으로 조회가 되었다.
dev tools로 돌아와 GET _cat/aliases 를 실행해보니 200 success 표시와 함께 .kibana_1.kibana .kibana_1 - - - - 라고 메시지가 출력되었다.
You could specify a version attribute for your mapped objects, and the mapper would automatically apply conditional constraints to give you optimistic locking, but you couldn’t explicitly specify your own custom conditional constraints with the mapper.
위 페이지를 읽어보면
dynamo DB는 기본적으로 version을 기준으로 logical condition을 검사한 뒤
테이블에 데이터를 저장한다고 나와있다.
실제 legacy코드에도 기존 데이터를 조회해서 version을 읽어와서
새 데이터 입력할 때 세팅해주고 있었다.
ok 그럼 뭔가 version충돌로 인해 데이터를 저장하지 못하고 있다는 추측을 해볼 수 있었다.
왜 충돌이 날까?
분산시스템에서 동일한 데이터의 업데이트 요청을 동시에 여러 개 받게 되면?
dynamo 테이블의 동일한 데이터를 동시에 업데이트를 하려고 시도를 하게 될 텐데,
실제로 업데이트 하기 전에 기존 version을 조회해와서 신규 데이터에 version 세팅을 해주고
업데이트를 시도하는데 처음 업데이트 시도는 성공! (이때 해당 데이터는 version이 올라가게 된다)
그 이후는 version충돌로 ConditionalCheckFailedException 예외가 발생하게 되는 것이다.